Data Model
This chapter introduces BanyanDB’s data models and covers the following:
- the high-level data organization
- data model
- data retrieval
You can also find examples of how to interact with BanyanDB using bydbctl, how to create and drop groups, or how to create, read, update and drop streams/measures.
Structure of BanyanDB
The hierarchy that data is organized into streams, measures and properties in groups.
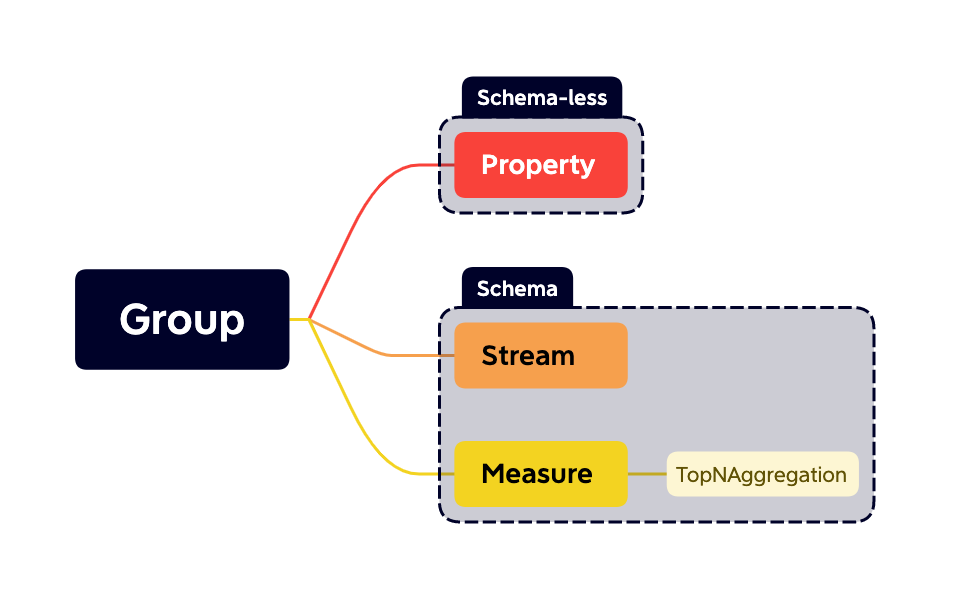
Groups
Group does not provide a mechanism for isolating groups of resources within a single banyand-server but is the minimal unit to manage physical structures. Each group contains a set of options, like retention policy, shard number, etc. Several shards distribute in a group.
metadata:
name: others
or
metadata:
name: sw_metric
catalog: CATALOG_MEASURE
resource_opts:
shard_num: 2
block_interval:
unit: UNIT_HOUR
num: 2
segment_interval:
unit: UNIT_DAY
num: 1
ttl:
unit: UNIT_DAY
num: 7
The group creates two shards to store data points. Every day, it would create a segment that will generate a block every 2 hours. The available units are HOUR and DAY. The data in this group will keep 7 days.
Every other resource should belong to a group. The catalog indicates which kind of data model the group contains.
Measures
BanyanDB lets you define a measure as follows:
metadata:
name: service_cpm_minute
group: sw_metric
tag_families:
- name: default
tags:
- name: id
type: TAG_TYPE_ID
- name: entity_id
type: TAG_TYPE_STRING
fields:
- name: total
field_type: FIELD_TYPE_INT
encoding_method: ENCODING_METHOD_GORILLA
compression_method: COMPRESSION_METHOD_ZSTD
- name: value
field_type: FIELD_TYPE_INT
encoding_method: ENCODING_METHOD_GORILLA
compression_method: COMPRESSION_METHOD_ZSTD
entity:
tag_names:
- entity_id
interval: 1m
Measure consists of a sequence of data points. Each data point contains tags and fields.
Tags are key-value pairs. The database engine can index tag values by referring to the index rules and rule bindings, confining the query to filtering data points based on tags bound to an index rule.
Tags are grouped into unique tag_families which are the logical and physical grouping of tags.
Measure supports the following tag types:
- STRING : Text
- INT : 64 bits long integer
- STRING_ARRAY : A group of strings
- INT_ARRAY : A group of integers
- DATA_BINARY : Raw binary
- ID : Identity of a data point in a measure. If several data points come with an identical ID typed tag, the last write wins according to the
timestamp.
A group of selected tags composite an entity that points out a specific time series the data point belongs to. The database engine has capacities to encode and compress values in the same time series. Users should select appropriate tag combinations to optimize the data size. Another role of entity is the sharding key of data points, determining how to fragment data between shards.
Fields are also key-value pairs like tags. But the value of each field is the actual value of a single data point. The database engine would encode and compress the field’s values in the same time series. The query operation is forbidden to filter data points based on a field’s value. You could apply aggregation
functions to them.
Measure supports the following fields types:
- STRING : Text
- INT : 64 bits long integer
- DATA_BINARY : Raw binary
Measure supports the following encoding methods:
- GORILLA : GORILLA encoding is lossless. It is more suitable for a numerical sequence with similar values and is not recommended for sequence data with large fluctuations.
Measure supports the types of the following fields:
- ZSTD : Zstandard is a real-time compression algorithm, that provides high compression ratios. It offers a very wide range of compression/speed trade-offs, while being backed by a very fast decoder. For BanyanDB focus on speed.
Another option named interval plays a critical role in encoding. It indicates the time range between two adjacent data points in a time series and implies that all data points belonging to the same time series are distributed based on a fixed interval. A better practice for the naming measure is to append the interval literal to the tail, for example, service_cpm_minute. It’s a parameter of GORILLA encoding method.
Measure Registration Operations
TopNAggregation
Find the Top-N entities from a dataset in a time range is a common scenario. We could see the diagrams like “Top 10 throughput endpoints”, and “Most slow 20 endpoints”, etc on SkyWalking’s UI. Exploring and analyzing the top entities can always reveal some high-value information.
BanyanDB introduces the TopNAggregation, aiming to pre-calculate the top/bottom entities during the measure writing phase. In the query phase, BanyanDB can quickly retrieve the top/bottom records. The performance would be much better than top() function which is based on the query phase aggregation procedure.
Caveat:
TopNAggregationis an approximate realization, to use it well you need have a good understanding with the algorithm as well as the data distribution.
---
metadata:
name: endpoint_cpm_minute_top_bottom
group: sw_metric
source_measure:
name: endpoint_cpm_minute
group: sw_metric
field_name: value
field_value_sort: SORT_UNSPECIFIED
group_by_tag_names:
- entity_id
counters_number: 10000
lru_size: 10
endpoint_cpm_minute_top_bottom is watching the data ingesting of the source measure endpoint_cpm_minute to generate both top 1000 and bottom 1000 entity cardinalities. If only Top 1000 or Bottom 1000 is needed, the field_value_sort could be DESC or ASC respectively.
- SORT_DESC: Top-N. In a series of
1,2,3...1000. Top10’s result is1000,999...991. - SORT_ASC: Bottom-N. In a series of
1,2,3...1000. Bottom10’s result is1,2...10.
Tags in group_by_tag_names are used as dimensions. These tags can be searched (only equality is supported) in the query phase. Tags do not exist in group_by_tag_names will be dropped in the pre-calculating phase.
counters_number denotes the number of entity cardinality. As the above example shows, calculating the Top 100 among 10 thousands is easier than among 10 millions.
lru_size is a late data optimizing flag. The higher the number, the more late data, but the more memory space is consumed.
TopNAggregation Registration Operations
Streams
Stream shares many details with Measure except for abandoning field. Stream focuses on high throughput data collection, for example, tracing and logging. The database engine also supports compressing stream entries based on entity, but no encoding process is involved.
Stream Registration Operations
Properties
Property is a schema-less or schema-free data model. That means you DO NOT have to define a schema before writing a Property
Property is a standard key-value store. Users could store their metadata or items on a property and get a sequential consistency guarantee. BanyanDB’s motivation for introducing such a particular structure is to support most APM scenarios that need to store critical data, especially for a distributed database cluster.
We should create group before creating a property.
Creating group.
metadata:
name: sw
Creating property.
metadata:
container:
group: sw
name: ui_template
id: General-Service
tags:
- key: name
value:
str:
value: "hello"
- key: state
value:
str:
value: "succeed"
Property supports a three-level hierarchy, group/name/id, that is more flexible than schemaful data models.
You could Create, Read, Update and Drop a property, and update or drop several tags instead of the entire property.
Data Models
Data models in BanyanDB derive from some classic data models.
TimeSeries Model
A time series is a series of data points indexed in time order. Most commonly, a time series is a sequence taken at successive equally spaced points in time. Thus it is a sequence of discrete-time data.
You can store time series data points through Stream or Measure. Examples of Stream are logs, traces and events. Measure could ingest metrics, profiles, etc.
Key-Value Model
The key-value data model is a subset of the Property data model. Every property has a key <group>/<name>/<id> that identifies a property within a collection. This key acts as the primary key to retrieve the data. You can set it when creating a key. It cannot be changed later because the attribute is immutable.
There are several Key-Value pairs in a property, named Tags. You could add, update and drop them based on the tag’s key.
Data Retrieval
Queries and Writes are used to filter schemaful data models, Stream, Measure or TopNAggregation based on certain criteria, as well as to compute or store new data.
MeasureServiceprovidesWrite,QueryandTopNStreamServiceprovidesWrite,Query
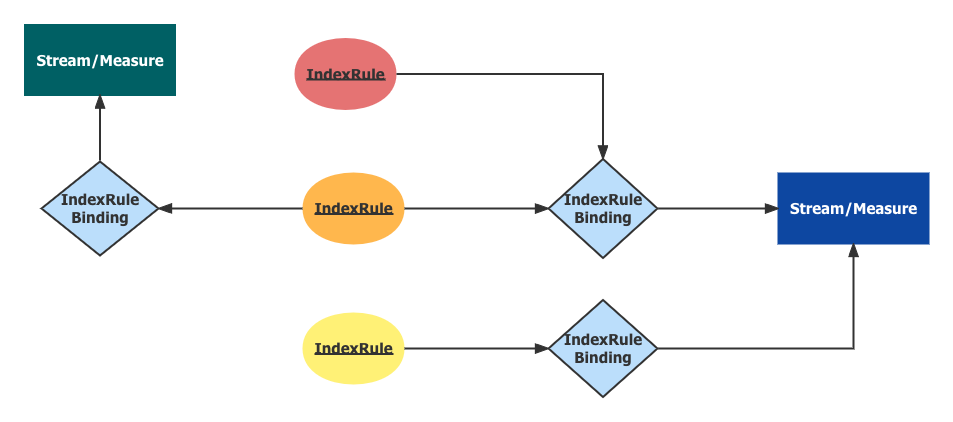
IndexRule & IndexRuleBinding
An IndexRule indicates which tags are indexed. An IndexRuleBinding binds an index rule to the target resources or the subject. There might be several rule bindings to a single resource, but their effective time range could NOT overlap.
metadata:
name: trace_id
group: sw_stream
tags:
- trace_id
type: TYPE_TREE
location: LOCATION_GLOBAL
IndexRule supports selecting two distinct kinds of index structures. The INVERTED index is the primary option when users set up an index rule. It’s suitable for most tag indexing due to a better memory usage ratio and query performance. When there are many unique tag values here, such as the ID tag and numeric duration tag, the TREE index could be better. This index saves much memory space with high-cardinality data sets.
Most IndexRule’s location is LOCAL which places indices with their indexed data together. IndexRule also provides a GLOBAL location to place some indices on a higher layer of hierarchical structure. This option intends to optimize the full-scan operation for some querying cases of no time range specification, such as finding spans from a trace by trace_id.
metadata:
name: stream_binding
group: sw_stream
rules:
- trace_id
- duration
- endpoint_id
- status_code
- http.method
- db.instance
- db.type
- mq.broker
- mq.queue
- mq.topic
- extended_tags
subject:
catalog: CATALOG_STREAM
name: sw
begin_at: '2021-04-15T01:30:15.01Z'
expire_at: '2121-04-15T01:30:15.01Z'
IndexRuleBinding binds IndexRules to a subject, Stream or Measure. The time range between begin_at and expire_at is the effective time.